Efficiently handle knowledge as a Computer Scientist
Discover how to efficiently manage research papers and technical knowledge as a computer scientist using Mendeley Desktop with strategic tagging, project organization, and cloud synchronization across multiple devices.


I love to learn. Each day. A bit more of what the world has to offer. I read a lot of technical stuff. I spend a lot of time reading about all kind of subjects, most of it being computer science / computer vision related.
I also have a really bad memory. If I rarely forget a face, I must say I have already forgotten 80% of the programming languages and libraries I haven't been working with for more than 10 days. I spent years with hundreds of bookmarks in my browser, classified into folders that would also contain other folders. . .
But if this could be a problem, my experience in research centers helped me find a nice workaround to highly increase my efficiency. Having no memory is no great deal, as soon as you are able to quickly process and find information. And a weak my long-term memory, as strong my need for organization.
As a researcher, part of your job consists in being an expert in your field and "keep both eyes open". Some of your time should be spent reading publications related (or not) to your curent projects. And most researchers I know have their own way to handle this big piece of "paper knowledge" they process. While being in TNO, I found one piece of tool that I never stopped using : Mendeley Desktop.
Basically speaking, Mendeley is a publication management tool. It would help you keep track of your publications by extracting meda-data from the pdfs, and sort them out for you. For each document, you can access its authors, abstract, . . . And you can also set these meta-data and add keywords or tags.
While keywords are often already filled by the authors of the pdfs, tags have become my very secret weapon.
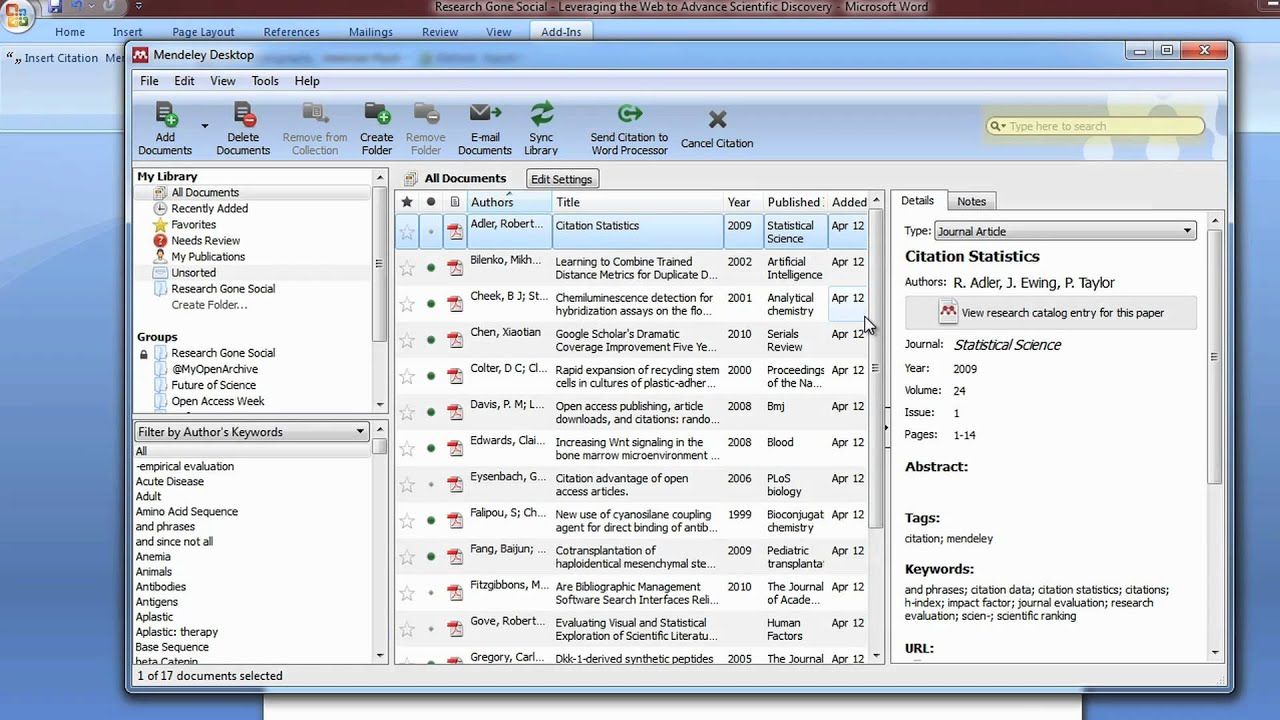
There are 3 major things I want to show you here that can help you efficiently handle tons of information.
First of all, the center part of the screen is dedicated to the list of pdfs you have in your library. And what I love is the small green circle you can find on the left part of the list. It shows whether you have already read the paper or not. This is very useful if you have to store a lot of papers in the same place (like me).
Then, the right part of the screen. It shows all the meta-data available for each pdf. Once I have finished to read a paper, I switch the green circle to grey to show that this information has been processed and I add some tags.
Here are the tags hierarchy I would always fill in :
- Name of the project for which this piece of information has been useful.
- Programming language used in the paper
- General information about the field of the article (web development, marketing, agile, . . .)
- Precise name of the module/library/tip (pickle, coding style, opencv, . . .)
- read tag, double check of the green circle (in case I want to access this piece of information using scripts).
Last but not least, the bottom right part of the screen is dedicated to document filtering. This is the tool I use to quickly find back some information that are already part of my "knowledge".
While working, I eventually have to search for some tips or module. Most of the time, I already know some of what I search, but need precisions (ex : I want to use memoization, but am not sure whether to use a dict or a list . . . ). I quickly jump to my second brain, ie. Mendeley and type the memoization keyword.
I would get the answer I search for immediately. Less than 1 minut later, my code is usually ready to go.
With time, I got rid of 95% of my web bookmarks. When I find some useful information on the web, I simply print the article as a pdf and store it into my knowledge database. Having Mendeley always open next to my code, this way of searching is way faster than finding a bookmark back in a browser :).
And as a bonus, your knowledge is also available offline, and you don't need your chrome persoc anymore :).
Some more information (BONUS part) :
As I code at work, in the train and also at home, my knowledge database has to be available in at least 3 different computers. Best of luck, Mendeley is pretty efficient and well developed, and as long as you don't use special characters you can use the software on different OSes without messing everything up (I tried Windows and Linux versions). What you have to do is to install the piece of software on each computer, and give Mendeley a folder to watch. I tried using a portable USB key to keep all my papers on the same place for some time, but it appear that it is greatly human-failure dependant (I kept forgettin' the damn key). What I use now for a complete real-time synchronization is simply a Dropbox folder. This way, everything is updated real-time (assuming you won't update the same file on different computers at the same time. . . ) on all your computers.
Another "similar" tool is Calibre, a pretty efficient library management tool. But I prefer using it only for ebooks, while using Mendeley for small ( not more than 100 pages) documents. Basically if it has a cover page, I'll put it in my Calibre database :).
Note : Mendeley has a lot more capabilities (publication sharing, friends wish list, . . . ) and what I present here is only a tiny part of the software. I don't use them though, and I think they are not into the frame of this article.
Your turn now, let me know about your own way of handling the huge quantity of information we have to deal with every day in CS !
Julien
UPDATE : You can join the group contaning my list of publication related to computer vision here!