Some fun with Kotlin, Exposed and MySQL
Some lessons learned from playing around with Kotlin, Exposed, SQL and the iMDB datasets.


We are living strange times right now. Playing around with new technology as half the world is on lockdown feels vain, and I struggle to put my mind to the task.
But I also can't let myself down, so here we are!
A couple months back, I built Star Recognizer, a simple Elm application that allows you to take a picture of a movie and know who are the actors playing in it. It is very crude still, but built on a real use case :). I have a good memory for faces, and always argue with my partner about such and such actor. Not any more!
One of the things that bugged me is that iMDB offers no open API, so it is not easy to provide much information in the app itself. Ideally, I would like something like : This is Heath Ledger, and he is most liked for The Dark Knight and The Imaginarium of Doctor Parnassus.
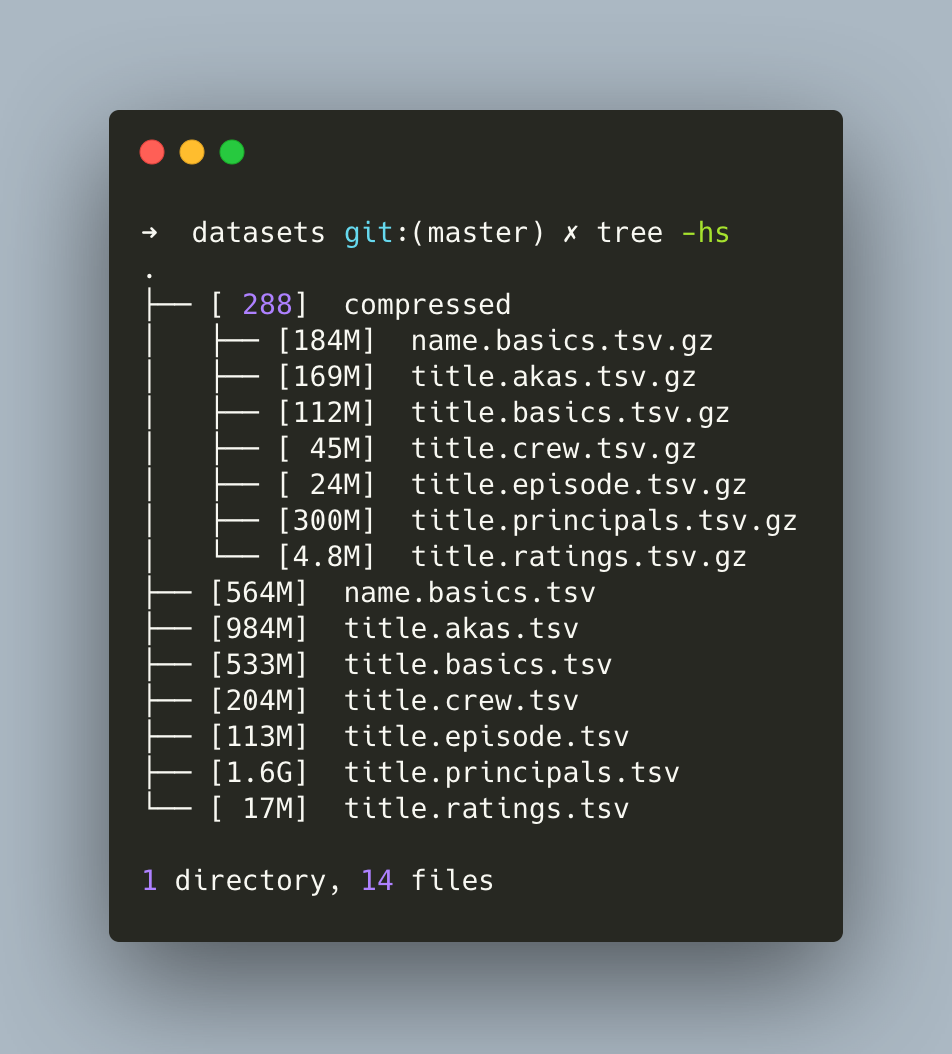
Then I saw that iMDB offered a daily snapshot version of their datasets and I felt like refreshing my SQL skills while doing some Kotlin.
The goal is to get a fully automated ingestion mechanism running on Docker that anyone can spin quickly, featured with a simple API that can be used. There are many options available, but for this project I decided to give Exposed a spin, which is a Kotlin SQL Framework from the folks at Jetbrains.
This article is a collection of tips and tricks I've learnt when playing around with Exposed. A proper post about the project will come later once I'm done :).
Importing large amounts of data in the database
Most of the examples indicated in the exposed documentation show the insertion of limited amounts of data in the database.
In my case, The total size of the dataset to be ingested is almost 4Gbs (1Gbs if taking only actors and movies in), for a total of over 87 Million lines (!!).
I was obviously not going to fit everything in a single transaction.
So I created a function that allows me to split a given dataset into multiple transactions, depending on its size :
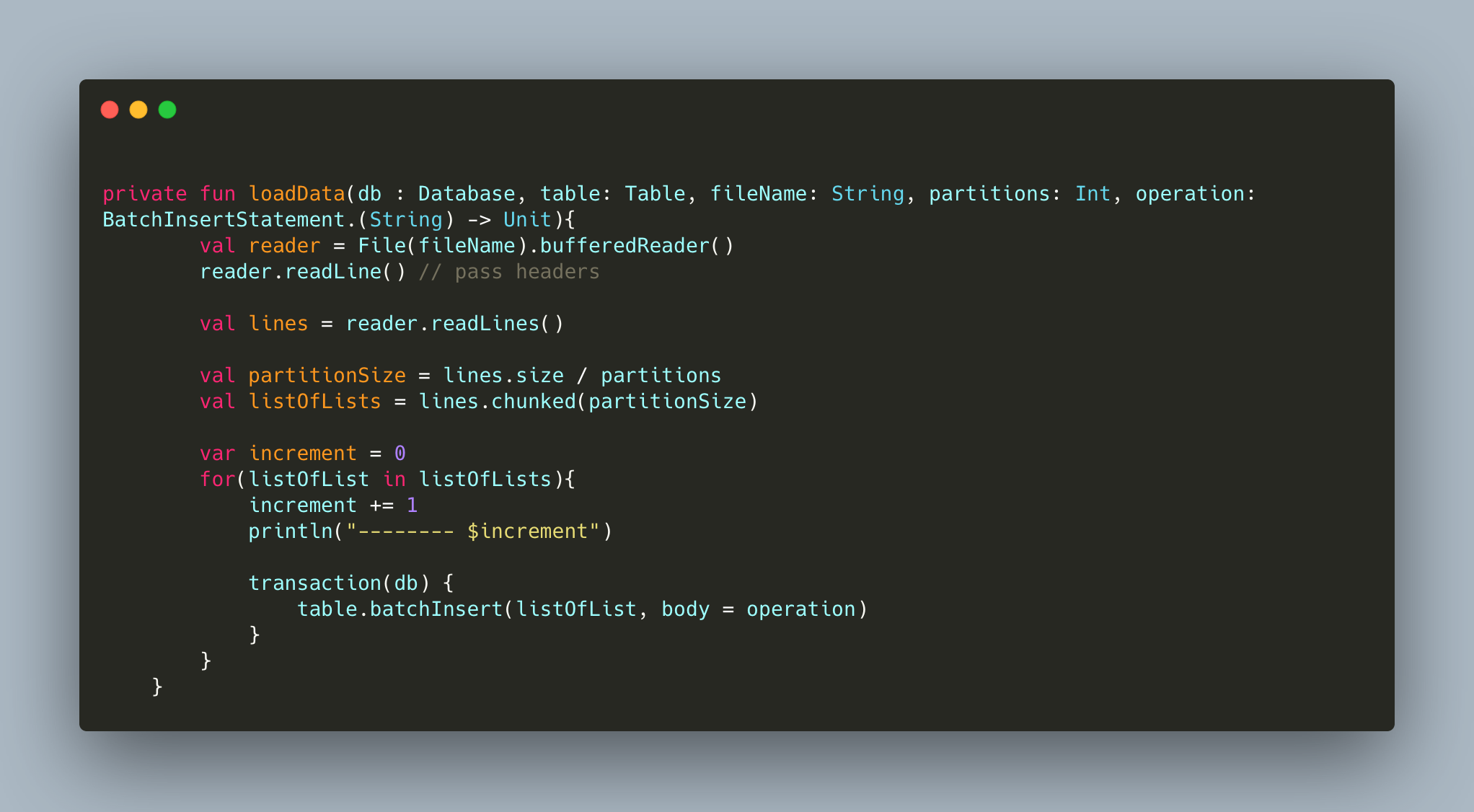
Disclaimer : I am totally not happy about that current function. It's definitely not idiomatic IMHO, and I'll come back to it later. But it does the job for now, and I want to focus on getting the API running in the short run.
I learnt two things while doing this :
- I had to revert to a
forloop to run the transaction. I originally had a.map()but this would eagerly keep all the file in memory, which would generateOut of Memoryexceptions. - Even though we are using the
batchInsertmethod from Exposed, what actually happens in the background is that we generate a single INSERT SQL statement per line in mySQL. An obviously not desired solution. The solution is to use therewriteBatchedStatements=trueand leverage MySQL to rewrite those statements. The improvement in my case was well over a 2000% speedup! Enough that I asked that note to be part of the official documentation.
Using references between tables
I am fortunate enough that iMDB uses nconst and tconst as unique identifiers of respectively actors and titles. Those unique ids can be found across the tables and we can make good use of it.
Here are definitions of my movie titles, and their ratings :
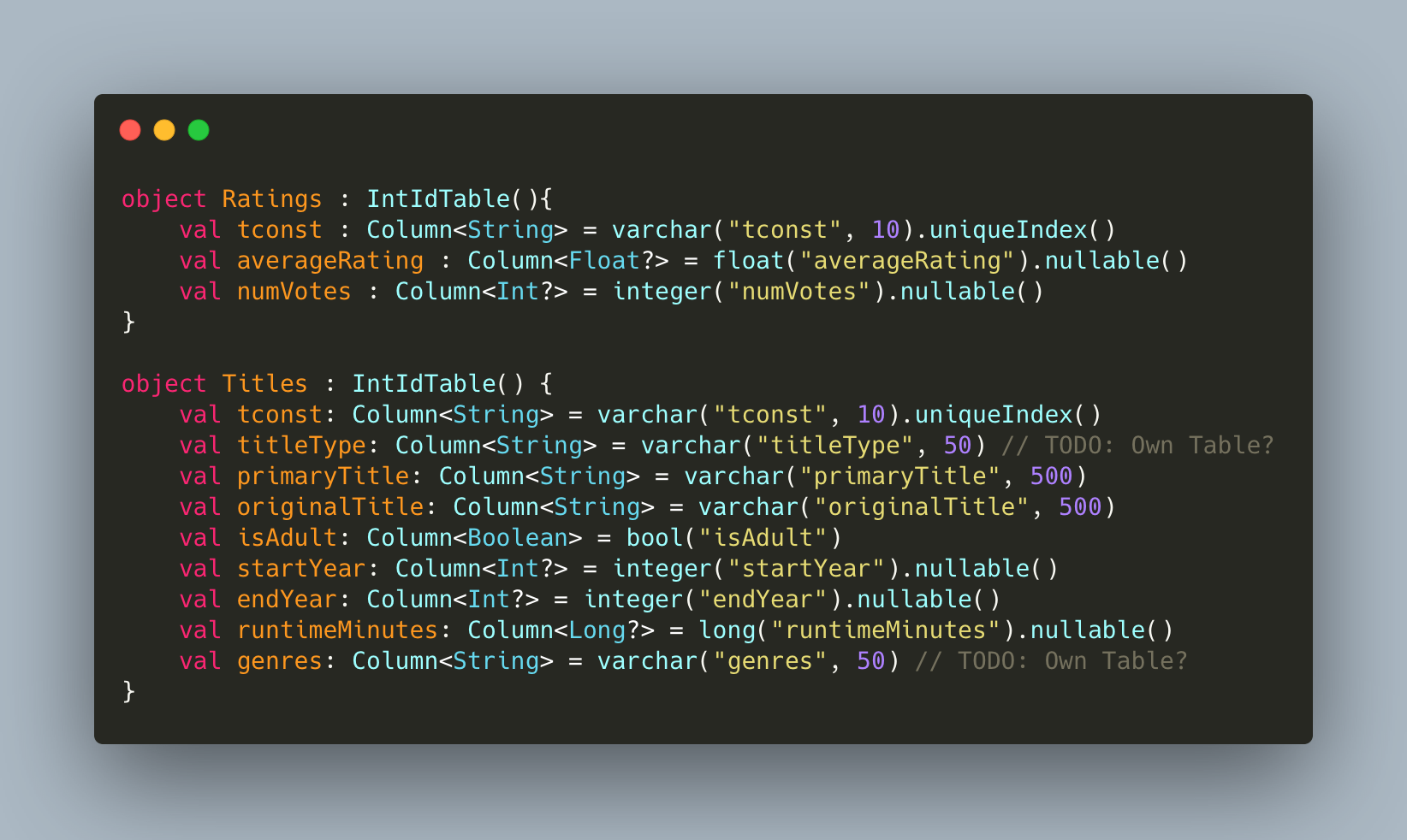
Now, let's try to find the first Batman movie by rating:
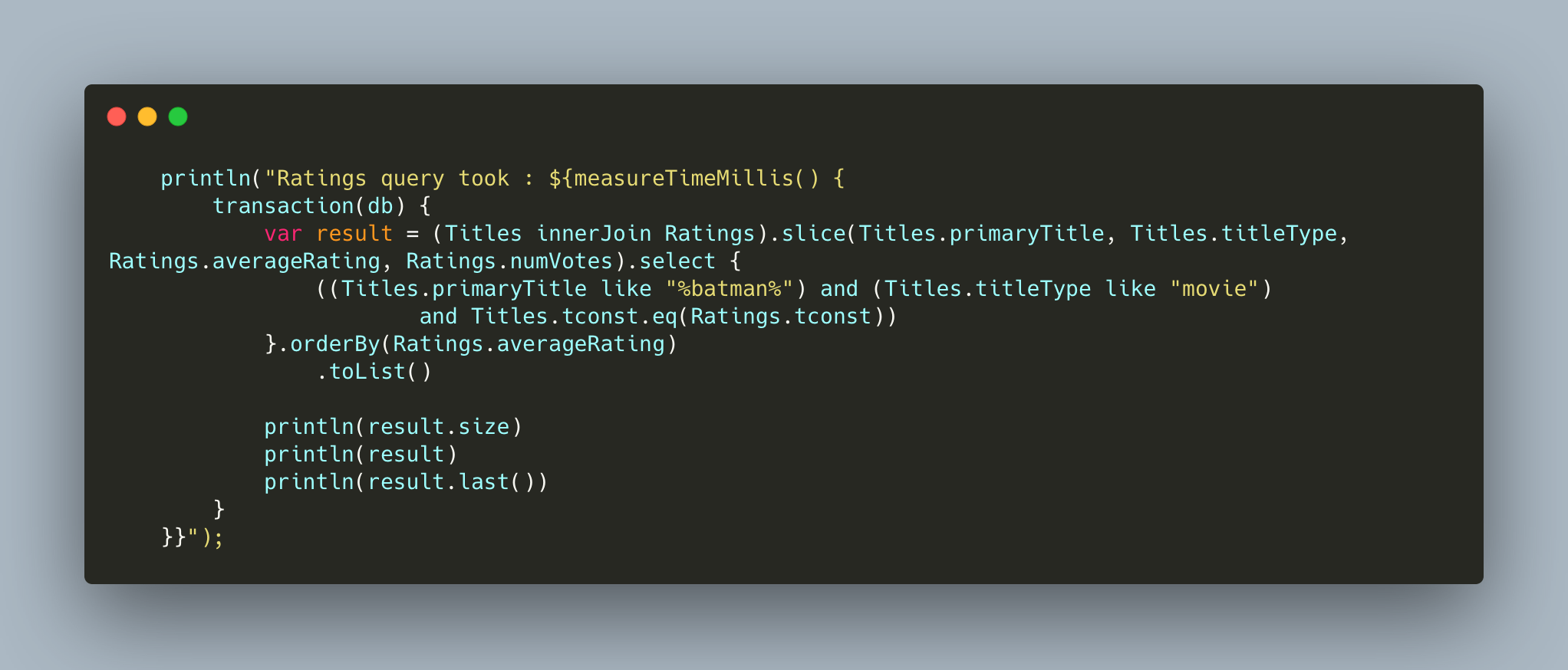
This query, on a fully loaded database, takes 3.1 seconds on average on my MBP.
Now, let us leverage references from the framework, and define a relation between the two tables. The only difference is that we define tconst as a reference to Ratings in the Titles table. So we will change our Titles object's first line to be :

The very same request takes now 2.1 seconds on average on my laptop. You really shouldn't do without :).
Using database options
The main Exposed README example gives an overview of operations that are being done as part of a database transaction.
- In my case, I do things always in at least two steps : I populate the database, and then I run the query, which means I was having two transactions. The H2 in-memory database was always failing at the second transaction, telling me that my table didn't exist. Well, turns out it is a well know thing. H2 will close the connection by default after the first transaction. The fix is actually quite simple : add the following option to the database to keep the connection open :
;DB_CLOSE_DELAY=-1. - Another simple but useful tip : On my local setup, the database connection is not setup to use HTTPS. Starting the MySQL connection would generate errors :
Establishing SSL connection without server's identity verification is not recommended. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
This is fixed as indicated simply by adding the following option to your connection string ?useSSL=false.
Data repetition makes schemes error prone
One of the things that kept biting me with Exposed so far is the fact that you feel like the same information is repeated several times across your application, making contract errors very easy if you copy/paste or are not focused enough.
This is especially true when marshalling / demarshalling my schemas .
Let's look at my Ratings table for example, and how to populate it :
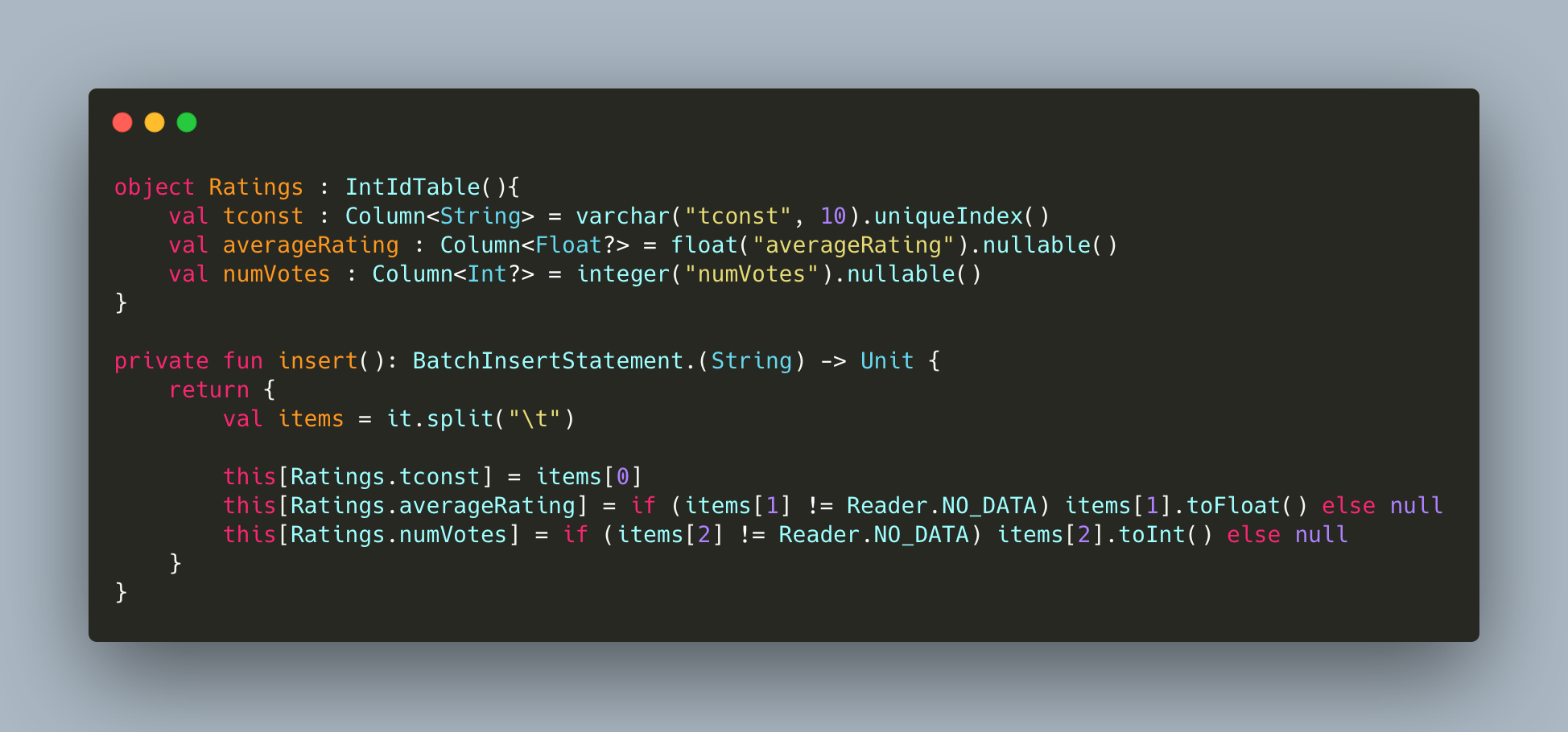
Just for clarity, because I am processing a TSV file, the insert function takes a line of the file and create an InsertStatement out of it.
If we look at averageRating for example, this specific name is used three different times in different places. It happened a few times that I mix a letter, or place the name in the wrong place, which can create bugs that are annoying to find. Especially since those two functions are typically placed in different files. This is an issue you are less likely to find with an annotation based system for example.
But again, this is a minor annoyance and the strong typing helps tremendously already anyways.
Conclusion
I am far from done with this project, as you can see, the snippets are still rough and there will be some refactoring coming. So far I have used the opportunity to investigate a new framework which I had not done in a while, and refresh my SQL knowledge in the process. Plus it can be fun and useful for some once it's done!
It is bar far not a complete project, but you can check the current status here :).
Till next time!